Diese Nachwuchsgruppe ist Teil der Graduate School of Excellence advanced Manufacturing Engineering (GSaME).
Projektbeschreibung
Informations- und Kommunikationstechnologie (IKT) hat produzierende Unternehmen in den letzten Jahren entscheidend verändert und wird auch in Zukunft eine wachsende Rolle spielen, was durch aktuelle Trends wie Industrie 4.0 und Digitalisierung beobachtet werden kann. Dieser Entwicklung trägt die Nachwuchsforschungsgruppe „IKT-Plattform für die Produktion" an der Graduate School of Excellence advanced Manufacturing Engineering (GSaME) Rechnung. Ein zentraler Beitrag der Nachwuchsforschungsgruppe ist die „Stuttgart IT Architecture for Manufacturing“ (SITAM). SITAM bietet eine über das ganze Produktionsunternehmen reichende Integrationsumgebung für heterogene Informationssysteme und deren Daten. Darauf aufbauend ermöglicht SITAM, sämtliche strukturierte und unstrukturierte Daten zu analysieren sowie Mitarbeiter über mobile Endgeräte und eine mobile Informationsbereitstellung noch stärker in den Produktionsprozess einzubinden.
Der aktuelle Forschungsschwerpunkt der Nachwuchsgruppe liegt primär darin, die von der SITAM-Architektur angebotenen Möglichkeiten zur Datenvorverarbeitung, Datenanalyse und zum maschinellen Lernen zu vertiefen. Zur Nachwuchsgruppe gehören zusätzlich zum Leiter auch GSaME-Doktorand*innen, die einen direkten Bezug zum Forschungsthema haben (siehe Abbildung). In Anlehnung an das duale Grundprinzip der GSaME verknüpft die Gruppe hierbei die Erzielung innovativer Forschungsergebnisse mit anwendungsnahen Problemstellungen. Dies wird unter anderem dadurch ersichtlich, dass viele der beteiligten Promotionsprojekte in Kooperation mit einem Industriepartner durchgeführt werden.
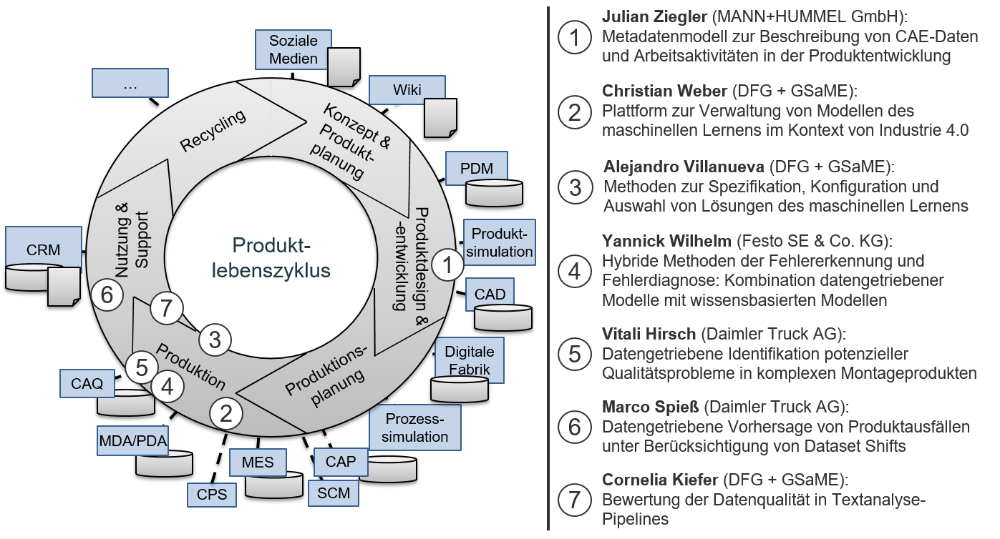
Bei den anwendungsnahen Forschungsprojekten fokussiert die Nachwuchsgruppe nicht nur auf die Produktion, sondern untersucht Daten und Potenziale für Datenanalysen in verschiedenen Phasen eines Produktlebenszyklus. In der Produktentwicklung können beispielsweise heterogene Simulationsdaten analysiert werden, um Empfehlungen für die Verbesserung eines Produktentwurfs herzuleiten. In der Phase Produktion kann eine Analyse von Sensordaten aus Prüfständen die Fehlerdiagnose und Identifikation von Qualitätsproblemen für defekte Produkte unterstützen. Ebenso kann mit Daten aus der Produktnutzung vorhergesagt werden, wann ein bestimmtes Produkt wahrscheinlich ausfällt. Dabei stellen sich die Fragen, welche Methoden zur Datenvorbereitung und Datenanalyse für die jeweiligen Daten eingesetzt und wie diese Methoden in Analyseprozessen kombiniert werden müssen. Hierbei zeigt sich, dass die spezifischen Charakteristika der jeweils verfügbaren industriellen Daten grundlegende Herausforderungen für gängige Datenanalysemethoden mit sich bringen. Bei einer datengetriebenen Fehlerdiagnose in der Produktion stehen oftmals nur sehr wenige nutzbare Daten zur Verfügung. Ebenso erhöht die hohe Produktvielfalt in Unternehmen gleichermaßen die Anzahl und Komplexität der in den Daten auftretenden Muster und Zusammenhänge.
Bei der Adressierung solcher Datencharakteristika ergeben sich einige grundlegende Forschungsfragen. Die Nachwuchsgruppe trägt zur Beantwortung dieser Fragen bei, indem sie neuartige, auf die spezifischen Datencharakteristika zugeschnittene Ansätze entwickelt. Ein zentraler Ansatz nutzt Domänenwissen in Form einer Produkthierarchie, um die Herausforderung der Produktvielfalt und die Komplexität der in Daten auftretenden Muster zu beherrschen. Ebenso entwickelt die Gruppe Methoden, um datengetriebene Modelle des maschinellen Lernens (ML-Modelle) mit physikalischen Simulationsmodellen oder anderen wissensbasierten Modellen, die von Ingenieur*innen erstellt wurden, zu verknüpfen. Hierbei ist das Ziel, die Genauigkeit von Vorhersagen in einem Entscheidungsunterstützungssystem zu erhöhen. Weiterer Forschungsgegenstand ist die Entwicklung eines adäquaten Metadaten-managements zur Verwaltung großer heterogener Datenmengen. Hierbei werden aber nicht nur Daten, sondern auch mit ihnen trainierte ML-Modelle über Metadaten beschrieben und mit ihrem Anwendungskontext verknüpft. Dieses Metadatenmanagement soll Domänenexpert*innen eine einfache und zielgerichtete Suche und Exploration nach Daten und ML-Modellen ermöglichen, die für ihre Problemstellungen geeignet sind. Ein weiterer Ansatz nutzt die Metadaten, um Anwender*innen bei der Auswahl und Konfiguration von Algorithmen des maschinellen Lernens sowie weiterer Datenvorbereitungstechniken zu unterstützen.
Die folgenden Promotionsprojekte sind Teil der Nachwuchsforschungsgruppe „IKT-Plattform für die Produktion":
- Vitali Hirsch: Datengetriebene Identifikation potenzieller Qualitätsprobleme in komplexen Montageprodukten (abgeschlossen)
- Cornelia Kiefer: Bewertung und Verbesserung der Datenqualität in Textanalyse-Pipelines (abgeschlossen)
- Christian Weber: Plattform zur Verwaltung von Modellen des maschinellen Lernens im Kontext von Industrie 4.0 (abgeschlossen)
- Alejandro Villanueva: Methoden zur Spezifikation, Konfiguration und Auswahl von Lösungen des maschinellen Lernens (abgeschlossen)
- Marco Spieß: Datengetriebene Vorhersage von Produktausfällen unter Berücksichtigung von Dataset Shifts (laufend)
- Yannick Wilhelm: Hybride Methoden der Fehlererkennung und Fehlerdiagnose: Kombination datengetriebener Modellen mit wissensbasierten Modellen (laufend)
- Julian Ziegler: Metadatenmodell zur Beschreibung von CAE-Daten und Arbeitsaktivitäten in der Produktentwicklung (laufend)

Peter Reimann
Dr. rer. nat.Wissenschaftlicher Angestellter